Rebuilding Unscripted's Backend To Move Faster
Leading a platform-wide architecture migration while keeping the product running for thousands of photographers.
- Product Management
- Software Engineering
- Leadership

The situation
Like a lot of platforms that grew fast in their early years, Unscripted's architecture was a patchwork — the result of different agencies, different technology bets, and shifting priorities across different stages. By the time I became Head of Product, the platform was carrying the scars of every growth-stage decision that had come before: three databases, two legacy frameworks, and a sync layer holding it all together with duct tape.
Our iOS and Android apps relied on data persisted across a range of sources. There was a MySQL database powering a Laravel app, Firebase for real-time mobile data, and our primary Postgres database behind a Rails app. A complex web of sync jobs was responsible for keeping all three in agreement.
On paper, this worked. In practice, it was a constant source of friction.

Data regularly fell out of sync. A photographer would update an invoice on the web, and their iOS app would show stale information — or worse, conflicting data. Customer support tickets would come in that were impossible to debug without tracing the sync chain. And every time we wanted to build something new, we weren't just building the feature, we were building an entire synchronisation layer on top of it, ensuring three databases stayed consistent through every possible state change.
This wasn't just a technical debt problem. It was a velocity problem. The sync architecture was the single biggest tax on our ability to ship product improvements. Every feature took longer than it should. Every release carried the risk of introducing new sync-related bugs. And the team was spending a meaningful amount of their energy maintaining infrastructure that shouldn't have existed in the first place.
Why this was hard to prioritise
The tricky thing about infrastructure work like this is that it doesn't show up on a feature request board. Photographers weren't asking us to "fix the sync layer." They were asking for better invoicing, more flexible contracts, and a smoother shoot management experience. The architecture was invisible to them until something broke.
But I could see that every one of those feature requests was going to take two or three times longer to deliver if we kept building on the existing foundation. Seemingly small product improvements would balloon into gigantic headaches because of the way data travelled through the platform. It came up in every technical discussion.
So the business case wasn't "fix the plumbing" — it was "unblock the next twelve months of product development."
Getting alignment on this meant being honest about the trade-off. We were going to spend 3-6 months building something that, from the outside, would look like nothing changed. The app would work the same way. The screens would look the same. But underneath, we'd have a platform we could actually build on.
The approach
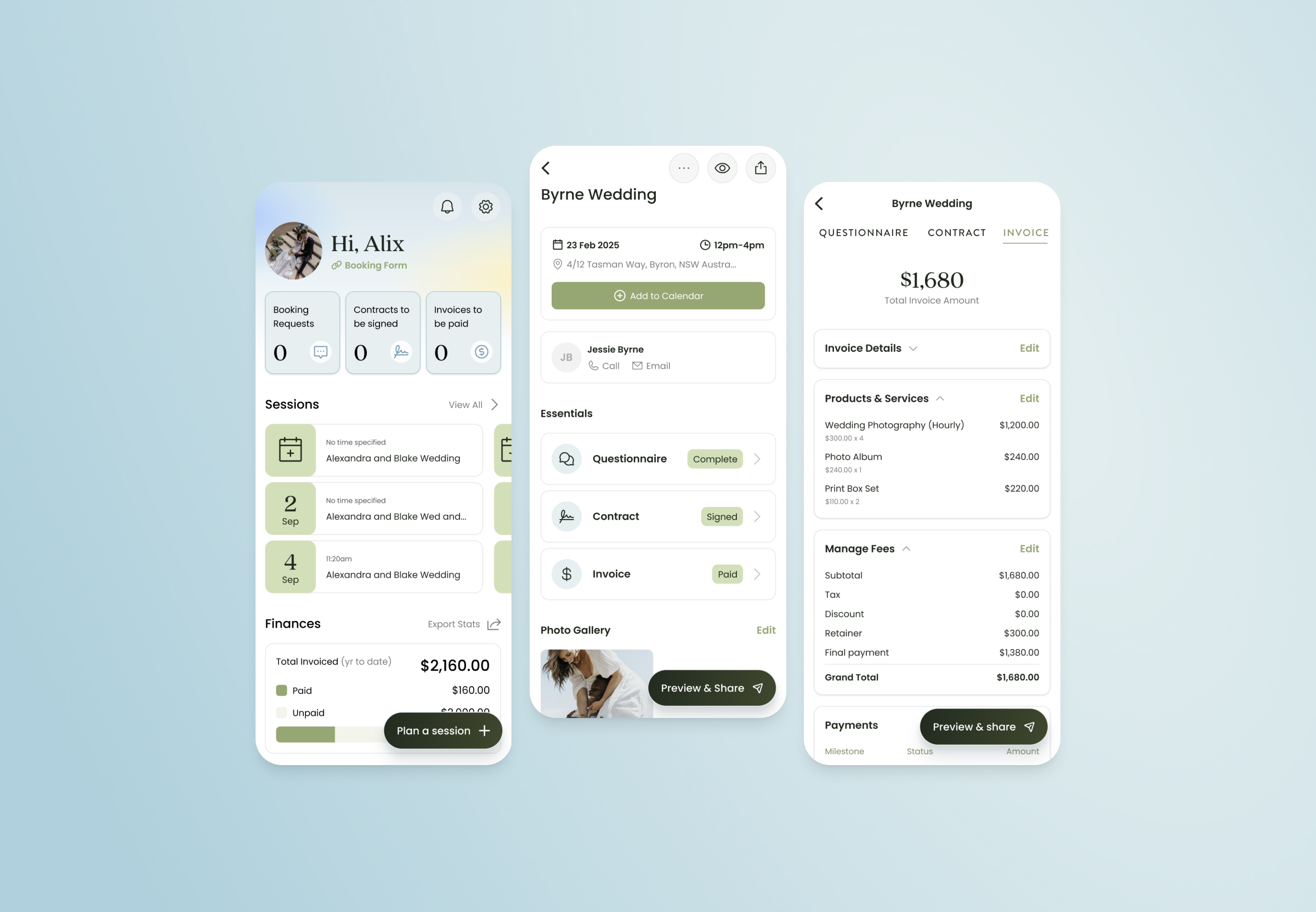
I led the scoping, execution plan, and rollout strategy for the entire project. The core idea was straightforward: migrate every piece of business functionality to consume data directly from our Postgres database via Rails API endpoints. In doing so, we would create a single source of truth for all data moving forward.
But "straightforward" and "simple" aren't the same thing. We had dozens of features touching these legacy systems — invoices, contracts, questionnaires, client management, shoots, email templates, checklists, and more. Not to mention the thousands of daily active users relying on these features to run their businesses. Migrating everything at once would have been reckless.
Phased rollout with feature flags
We grouped every core feature behind its own feature flag — contracts_v2, invoices_v2, clients_v2, photoshoots_v2, and so on. Each flag could be rolled out independently, tested in isolation, and rolled back if we hit issues.
This gave us two critical things: the ability to ship continuously without big-bang risk, and a clear way to communicate progress to the team.
Prioritising by impact
The sequencing was deliberate. We worked through the leaf nodes first — questionnaires, contracts, invoices — because they could be migrated and validated in relative isolation. Then we swept up the lower-traffic features.
Photoshoots came last, not because they were less important (they were our single highest-touch feature), but because they sat at the centre of the dependency graph. Every other migration fed into it. By the time we got there, the surrounding pieces were already stable, which made the riskiest migration the smoothest.
Managing data inconsistency
The biggest risk was data that had drifted out of sync over time. For new users this wasn't an issue, but long-time photographers almost certainly had records where Firebase, MySQL, and Postgres disagreed.
We controlled this through careful staged rollouts, with customer support briefed on each flag before it went live. We relied heavily on an awesome product called Flipper, which gave us visibility into feature flag status per user, the ability to increment rollouts gradually, and the option to roll back instantly if something went wrong.
The rollout wasn't seamless — we knew it wouldn't be. As each feature flag went live, existing gaps in the sync layer surfaced through customer support. We treated each one as a triage loop: identify the issue, patch the underlying cause, migrate affected data where necessary, and keep moving. The staged approach meant these were contained fires, not a blaze.
The team
I was accountable for the project end-to-end — scoping, prioritisation, managing the engineering team through execution, coordinating with design on the UI overhaul that followed, and communicating progress to leadership.
The engineering team (Alessandro, Damian, and later Eugene) did the heavy lifting on implementation. Elli led the design work for the subsequent UI refresh. We ran the project over roughly nine months: the API rebuild from March to September 2025, followed by a UI overhaul from October to December 2025 that brought our newly-rebuilt views in line with our modern design system using TCA and SwiftUI.
What changed
The numbers tell an interesting story. Since the rollout began, our average churn rate has dropped by nearly 19% year-over-year — a sustained, month-over-month decline that tracks closely with the migration timeline. It would be an overclaim to attribute that entirely to the architecture work, but the logic connects: data inconsistencies erode trust, and photographers who can't rely on their tools to show accurate information will eventually stop paying for them. Fixing the foundation removed a category of problems that users shouldn't have been experiencing in the first place.
Beyond churn, the real impact was in what we could do next. Before this project, every new feature required us to think about three databases. After it, we had a single source of truth, a clean API layer, and an engineering team conditioned to an API-first workflow. The invoicing improvements we shipped later that year — flexible line items, quantities, custom descriptions — would have taken significantly longer and been significantly riskier on the old architecture. The same goes for everything else on our roadmap.
This project didn't have a flashy launch. It was quietly announced internally as we incrementally moved each feature flag to 100% rollout — week after week. The UI overhaul that followed immediately demonstrated the payoff: we were able to redesign and rebuild our most-used business screens in under a month, something that would have been unthinkable before.
What I learned
Infrastructure migrations are a leadership problem, not just a technical one. The hardest part wasn't the code — it was building conviction across the team that this was worth doing now, maintaining momentum through months of work that didn't produce visible results, defending it as a priority when new opportunities emerged, and knowing when we'd done enough.
Small choices compound. Nobody made a bad decision that created this problem. Every piece of the architecture made sense when it was built. But small, pragmatic choices compound — and eventually the patchwork becomes the bottleneck. The difficult part is saying "this isn't working," and fixing the hard problems before they strangle your roadmap.
Feature flags are an underrated project management tool. By treating each feature migration as an independent, reversible unit of work, we de-risked the entire project. It also gave us natural checkpoints to evaluate whether to keep going or shift focus.
What’s Next
The tricky thing about mobile apps is that you can't force everyone to update. While the new architecture is fully rolled out on both iOS and Android, there are still users on older versions quietly reading from the legacy databases. So as satisfying as it would be to delete them in a blaze of glory — we can't. Not yet.
The synchronisation layer is still running — still dutifully keeping the legacy databases in step with Postgres, every second of every day. We'll retire it the same way we replaced it: gradually, deliberately, until one day it's finally silent.
